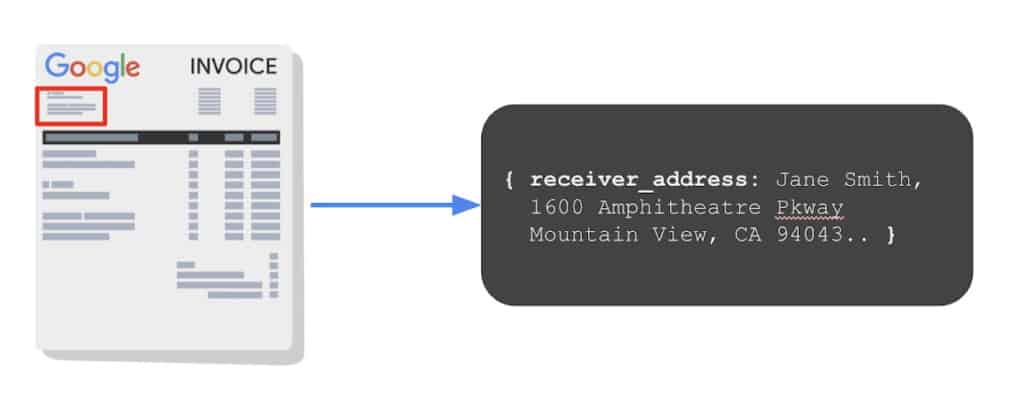


大手デジタル広告サービスとの1年にわたるRPAの旅を垣間見る
大手デジタル広告サービス・ソリューションプロバイダーの1年にわたるRPAの旅と、NashTechがどのように彼らを支援したかをご紹介します。

デジタル棚の分析をサポートし、eコマースの成長を引き出す
NashTechがどのようにデジタル棚の分析を支援し、世界有数のデータ洞察とeコマースソリューションプロバイダーと成長を解き放つかをご覧ください。











めまぐるしく変化する世界をナビゲートする
スケールとスピードで変革する
データの未開拓の可能性を実現する
データ資産を活用する
デジタル投資を最適化し、成長させる
エンドツーエンドのアプリケーション管理
ビジネスプロセスを管理し、オペレーションコストを削減する
お客様のシステムおよびソフトウェアの独立したテスト
最適な顧客体験を実現するためにデジタル資産を再設計する
NashTechのニュースやアナウンスメントの最新情報をお届けします。
NashTechとお客様から得た最新の専門知識とソートリーダーシップ
テクノロジー・リーダーシップに関する最新の世界最大かつ最も長期にわたる調査からの知見を探る

NashTechの多彩なリーダーシップチーム
グローバルなプロフェッショナル・サービス組織で、3つの主要分野に注力している。
NashTechのベトナムオフィスの360度全方位バーチャルツアーをご体験ください。
環境、社会、政府へのコミットメントをご覧ください
多様性、平等、インクルージョンを企業文化に組み込む

当社のグローバルオフィスと卓越したイノベーションセンターをご覧ください
大手デジタル広告サービス・ソリューションプロバイダーの1年にわたるRPAの旅と、NashTechがどのように彼らを支援したかをご紹介します。
NashTechがどのようにデジタル棚の分析を支援し、世界有数のデータ洞察とeコマースソリューションプロバイダーと成長を解き放つかをご覧ください。
Your contact request was submitted successfully. A member of our team will be in touch within one business day. If your enquiry is urgent please email info@nashtechglobal.com.